| 🚀 问题类别 | ❌ 传统方法的局限 | ✅ DDPM 的解决方案 |
|---|
| 生成模型的质量与稳定性 | 🚨 GANs 训练不稳定,易出现模式崩溃
🚨 VAEs 生成质量有限,样本模糊 | ✨ 非对抗性训练框架,避免 GANs 的不稳定性
✨ 逐步“加噪-去噪”过程,生成高质量样本 |
| 复杂数据分布的建模 | 🚨 GANs、VAEs、Flow 难以精确建模复杂数据分布
🚨 高分辨率图像生成困难 | ✨ 前向过程:数据逐步扰动为高斯噪声(马尔可夫链)
✨ 反向过程:去噪恢复数据分布 |
| 生成过程的可控性与渐进性 | 🚨 常见生成模型生成结果一成不变,缺乏细节控制
🚨 很难逐步提升生成样本质量 | ✨ 采用渐进式“有损压缩”视角
✨ 类似自回归模型的解码,允许逐步细化生成结果 |
🎯目的:
将不可微的采样操作变为可微的确定性变换,从而支持反向传播
💡基本思想:
将随机变量的采样过程分解为:
- 确定性部分:由模型参数决定的可微函数
- 随机性部分:从固定、简单分布(如标准正态)中采样的噪声变量
高斯分布中的重参数化形式:
X=μ+σ⋅ϵ,ϵ∼N(0,1)
可微性分析:
∂μ∂X=1,∂σ∂X=ϵ
进而支持对 μ 和 σ 的梯度计算
| 项目 | 无重参数化 | 有重参数化 |
|---|
| 采样方式 | 直接从分布 N(μ,σ2) 中采样 x | 从 ϵ∼N(0,1) 采样,再计算 x=μ+σ⋅ϵ |
| 随机变量是否可微 | ❌ 不可微(采样操作断开了计算图) | ✅ 可微(采样来自固定分布,变换是可微函数) |
| 是否支持反向传播 | ❌ 不支持,梯度无法传播到 μ, σ | ✅ 支持,梯度可传递到分布参数 |
| 是否能用于梯度优化 | ❌ 不可直接优化概率模型参数 | ✅ 可使用梯度下降等方法优化分布参数 |
| 常见用途 | 传统的随机采样、模拟等 | 变分自编码器(VAE)、可微分采样过程 |
在正向过程中,数据 x0 被逐步加入噪声,形成 x1,x2,...,xT
借由该特点(Eq.(4))得知:任意时刻的状态 xt,可以不通过逐步采样,而是直接由原始数据 x0 和噪声调节参数序列 {βt} 推出:
xt=αˉt⋅x0+1−αˉt⋅ϵ,ϵ∼N(0,I)
其中 αˉt=∏i=1t(1−βi)
🎯意义:
- 避免逐步执行 t 次采样(即一行公式即可模拟 t 时刻的加噪结果)
- 有利于训练过程中的 目标重构 loss 构造
将原始的变分下界简化为一个统一的 MSE 损失项:
Lsimple(θ)=Et,x0,ϵ[ϵ−ϵθ(αˉtx0+1−αˉtϵ,t)2]
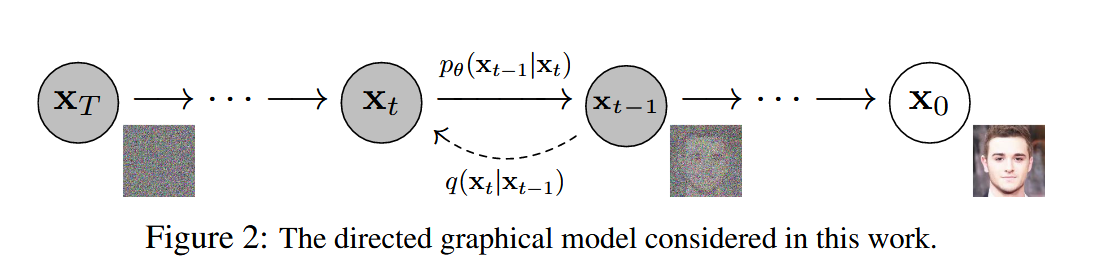
DDPM(Denoising Diffusion Probabilistic Models,后简称扩散模型) 的工作流程如下图所示:
简要地讲,扩散模型是一种参数化的 马尔可夫链(parameterized Markov chain),通过 变分推断(variational inference) 进行训练,以在有限时间内生成与数据分布相匹配的样本
模型通过学习 正向扩散过程(即马尔可夫链从原始数据逐步加噪直至信号被破坏)的转移规则,实现对这一过程的逆转(得到反向扩散过程,sample)
如果在正向扩散过程中,每一步添加的噪声都是 小量的高斯噪声,那么反向的采样过程也可以被建模为 条件高斯分布(Conditional Gaussian)
扩散模型是一个 潜变量模型(latent variable models),其形式为:
pθ(x0):=∫pθ(x0:T)dx1:T
其中,x1,…,xT 是与数据 x0 维度相同的潜变量,x0∼q(x0)
联合分布 pθ(x0:T) 被称为 反向过程(reverse process),它被定义为一个马尔可夫链,其高斯转移由模型学习得出,并从 p(xT)=N(xT;0,I) 开始:
pθ(x0:T)=p(xT)t=1∏Tpθ(xt−1∣xt),pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))(1)
边缘概率密度
对于连续型随机变量 (X,Y),设它的概率密度为 f(x,y)
其关于 X 的边缘概率密度为:
fX(x)=∫−∞∞f(x,y)dy
同理,关于 Y 的边缘概率密度为:
fY(y)=∫−∞∞f(x,y)dx
推导过程
⭐推导:
pθ(x0):=∫pθ(x0:T)dx1:T
xT 表示纯高斯噪声,x0 表示生成的样本
pθ(x0) 表示我们最终从扩散模型生成的数据 x0 的概率分布
θ 代表的是模型的可训练参数,通常是用于参数化神经网络的权重
由于整个扩散过程拆分成了马尔科夫链,现有 x0,⋯,xT 共 T+1 个随机变量,其联合概率密度为 pθ(x0,x1,⋯,xT),在论文中简写为 pθ(x0:T)
pθ(x0) 即为联合概率密度 pθ(x0:T) 中关于 x0 的边缘概率密度
由边缘概率密度的定义:
pθ(x0)=∫pθ(x0:T)dx1dx2…dxT=∫pθ(x0:T)dx1:T
概率的乘法公式
一般,设 A1,A2,⋯,An 为 n 个事件,n≥2,且 P(A1,A2,⋯,An−1)>0,则有:
P(A1A2⋯An)=P(An∣A1A2⋯An−1)P(An−1∣A1A2⋯An−2)⋯P(A2∣A1)P(A1)
马尔可夫链
随机过程 {Xn,n=0,1,2,…} 称为马尔可夫链,若随机过程在某一时刻的随机变量 Xn 只取有限或可列个值(比如非负整数集合,若不另作说明,以集合 S 表示),并且对于任意的 n≥0,及任意状态 i,j,i0,i1,…,in−1∈S,有:
P(Xn+1=j∣X0=i0,X1=i1,…,Xn=i)=P(Xn+1=j∣Xn=i)
其中,Xn=i 表示过程在时刻 n 处于状态 i;S 为该过程的状态空间
推导过程
⭐推导:
pθ(x0:T)=p(xT)t=1∏Tpθ(xt−1∣xt)
联合分布 pθ(x0:T) 被定义为一个马尔可夫链
pθ(x0:T)=p(xT)pθ(xT−1∣xT)pθ(xT−2∣xTxT−1)⋯pθ(x0∣x1:T−1)(乘法公式反向分解)=p(xT)pθ(xT−1∣xT)pθ(xT−2∣xT−1)⋯pθ(x0∣x1)(马尔可夫链定义)=p(xT)t=1∏Tpθ(xt−1∣xt)
pθ(x0:T) 无 θ 角标,是因为它代表扩散过程的 固定初始噪声分布,不涉及可学习参数。模型的参数化仅作用于反向步骤 pθ(xt−1∣xt)
转移概率的概率密度函数 pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t)) 是关于 xt−1 的一个高斯分布,其均值 μθ(xt,t) 与 Σθ(xt,t) 是关于 xt,t 的函数,其值通过学习得到
⭐解释:
pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))
为什么 pθ(xt−1∣xt) 是一个高斯分布?
由参考文献 [53],大多数扩散模型的正向过程与反向过程可由同一个函数形式描述
正向过程是由人为逐步添加小量的高斯噪声得到的一个高斯分布,故反向过程应与正向过程同为高斯分布
扩散模型与其他潜变量模型的区别是:
近似后验分布 q(x1:T∣x0) ,即 正向过程(forward process)(或是 扩散过程(diffusion process)),被固定为了一个马尔可夫链
该过程通过逐步添加高斯噪声,使得数据从真实分布逐渐扩散到一个标准正态分布
噪声的方差由一个预定义的调度参数 β1,⋯,βT 控制:
q(x1:T∣x0)=t=1∏Tq(xt∣xt−1),q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)(2)
条件概率公式
P(B∣A)=P(A)P(AB)
推导过程
⭐推导:
q(x1:T∣x0)=t=1∏Tq(xt∣xt−1)
q(x1:T∣x0)=q(x0)q(x0:T)=q(x0)q(x0)q(x1∣x0)q(x2∣x1x0)⋯q(xT∣x0:T−1)=q(x0)q(x0)q(x1∣x0)q(x2∣x1)⋯q(xT∣xT−1)=q(x1∣x0)q(x2∣x1)⋯q(xT∣xT−1)=t=1∏Tq(xt∣xt−1)
⭐解释:
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)
正向过程的分布是人为确定为上述形式的
训练是通过优化负对数似然的常规 变分下界(Evidence Lower Bound, ELBO) 来进行的:
E[−logpθ(x0)]≤Eq[−logq(x1:T∣x0)pθ(x0:T)]=Eq[−logp(xT)−t≥1∑logq(xt∣xt−1)pθ(xt−1∣xt)]=L(3)
Jensen 不等式
Jensen 不等式适用于 凹函数 f(x),即对于任意随机变量 X 和其概率分布 p(x):
f(E[X])≥E[f(X)]
当 f(x) 是 凸函数 时,方向相反
期望
设连续型随机变量 X 的概率密度为 f(x),若积分
∫−∞+∞xf(x)dx
绝对收敛,则称积分 ∫−∞+∞xf(x)dx 的值为随机变量 X 的数学期望,记为 E(X),即
E(X)=∫−∞+∞xf(x)dx
推导过程
⭐推导:
E[−logpθ(x0)]≤Eq[−logq(x1:T∣x0)pθ(x0:T)]=Eq[−logp(xT)−t≥1∑logq(xt∣xt−1)pθ(xt−1∣xt)]
目标函数:E[−logpθ(x0)]
最小化 负对数似然(Negative Log Likelihood, NLL),即 最大化数据的对数似然 E[logpθ(x0)]
- pθ(x0) 表示我们最终从扩散模型生成的数据 x0 的概率分布
- 直接最小化它通常是不可行的,因为计算 pθ(x0) 需要求解复杂的积分
- 这里是最大似然估计的概念补充
优化策略:变分推断(使用变分推断引入上界来优化)
引入一个辅助分布 q(x1:T∣x0)(即近似后验分布,正向扩散过程)进行变分推断来帮助估计对数似然
由 Eq.(1) : logpθ(x0)=log∫pθ(x0:T)dx1:T,借由辅助分布 q(x1:T∣x0) 得到:
logpθ(x0)=log∫q(x1:T∣x0)q(x1:T∣x0)pθ(x0:T)dx1:T
我们设:
X=q(x1:T∣x0)pθ(x0:T)
那么原式就变成:
logpθ(x0)=logEq(x1:T∣x0)[X]
注
这个期望的下标 q(x1:T∣x0) 表示关于随机变量 x1:T 的期望,其中这些变量的分布由 q(x1:T∣x0) 给出
Eq(x1:T∣x0) 是相对于 q(x1:T∣x0) 计算的期望,定义如下:
Eq(x1:T∣x0)[f(x1:T)]=∫q(x1:T∣x0)f(x1:T)dx1:T
这里,我们的函数是:
f(x1:T)=logq(x1:T∣x0)pθ(x0:T)
所以:
Eq(x1:T∣x0)[logq(x1:T∣x0)pθ(x0:T)]=∫q(x1:T∣x0)logq(x1:T∣x0)pθ(x0:T)dx1:T
因为 log(x) 是凹函数,我们可以对上式使用 Jensen 不等式:
logEq(x1:T∣x0)[X]≥Eq(x1:T∣x0)[logX]
注
因为对数函数 log(x) 是凹函数,由 Jensen 不等式:
logE[X]≥E[logX]
这个结论很关键,它意味着:如果我们有一个期望的形式 E[X],对它取对数后总是大于等于对数的期望
代入 X=q(x1:T∣x0)pθ(x0:T),我们得到:
logpθ(x0)≥Eq(x1:T∣x0)[logq(x1:T∣x0)pθ(x0:T)]
这就是 ELBO(变分下界),也是变分推断的核心结论
由 Eq.(1)(2) 展开期望中的对数项:
logq(x1:T∣x0)pθ(x0:T)=logp(xT)+t≥1∑logq(xt∣xt−1)pθ(xt−1∣xt)
最后得到需要优化的 L
正向过程的方差 βt 可以通过 重参数化(reparameterization) 进行学习,也可以作为超参数保持不变。而反向过程的表达能力部分通过在 pθ(xt−1∣xt) 中选择高斯条件分布来确保,因为当 βt 较小时,两个过程具有相同的函数形式。正向过程的一个显著特点是,它允许在任意时间步 t 对 xt 进行封闭形式的采样:记 αt=1−βt 和 αˉt=∏s=1tαs,我们有:
q(xt∣x0)=N(xt;αtˉx0,(1−αtˉ)I)(4)
重参数化
重参数化(Reparameterization) 是一种数学技巧,用于将一个随机变量的采样过程分解为:
确定性部分(可微的参数化变换)
随机性部分(来自一个固定、简单的分布)
其核心目的是让随机变量的生成过程对参数可微,从而支持基于梯度的优化(如深度学习中的反向传播)
假设我们有一个随机变量 x,它服从某个参数化分布(如高斯分布 x∼N(μ,σ2))
直接采样 x 是不可微的(因为采样是一个随机操作,无法计算梯度)
重参数化的思路:
将采样过程重新表述为一个由噪声变量和模型参数决定的确定性函数。我们不再直接从分布中采样,而是从一个简单且固定的分布(如标准正态分布)中采样一个噪声变量,然后通过一个确定性的变换函数来计算采样值
然后通过一个确定性变换 g(θ,ϵ) 生成 X,使得 X 仍然服从目标分布,但梯度可以计算
在高斯分布的重参数化中,确定性变换 g(θ,ϵ)是将参数 θ=(μ,σ) 和基础噪声 ϵ 映射到目标随机变量 X 的数学表达式。具体形式为:
X=g(θ,ϵ)=μ+σ⋅ϵ,ϵ∼N(0,1)
高斯分布的性质决定了其重参数化可以通过简单的线性变换实现:
平移(+μ):调整均值
缩放(×σ):调整方差
变换后的 X 仍严格服从 N(μ,σ2),因为:
E[X]=μ+σ⋅E[ϵ]=μ,Var(X)=σ2⋅Var(ϵ)=σ2
重参数化的核心优势是可微性。对 θ=(μ,σ) 的梯度为:
\frac{\partial X}{\partial \mu} = 1, \quad \frac{\partial X}{\partial \sigma} = \epsilon $$ 梯度可通过反向传播计算,而 $\epsilon$ 被视为常量(因其来自固定分布)
推导过程
⭐推导:
q(xt∣x0)=N(xt;αtˉx0,(1−αtˉ)I)
由 Eq.(2):q(xt∣xt−1)=N(xt;1−βtxt−1,βtI),利用重参数化展开得到:
xt=αtxt−1+βtϵt−1,whereϵt−1∼N(0,I)
其中记 αt=1−βt
对 xt−1 继续递推展开:
xt−1=αt−1xt−2+βt−1ϵt−2
将 xt−1带入 xt 的表达式中:
xt=αt(αt−1xt−2+βt−1ϵt−2)+βtϵt−1=αtαt−1xt−2+αtβt−1ϵt−2+βtϵt−1
对 xt−2 继续递推展开:
xt−2=αt−2xt−3+βt−2ϵt−3
将 xt−2带入 xt−1 的表达式中:
xt=αtαt−1αt−2xt−3+αtαt−1βt−2ϵt−3+αtβt−1ϵt−2+βtϵt−1
最终得到 xt 的表达式:
xt=αˉt(s=1∏tαs)x0+i=1∑t噪声系数(βij=i+1∏tαj)ϵi−1
其中记 αˉt=∏s=1tαs
推导过程(续)
下面利用数学归纳发证明 ∑i=1t(βi∏j=i+1tαj)ϵi−1∼N(0,1−αˉt)
因为 ϵi−1∼N(0,I) 独立同分布,有:
Var(i=1∑t(βij=i+1∏tαj)ϵi−1)=i=1∑t(βij=i+1∏tαj)2⋅Var(ϵi−1)
注
下面是有关方差的一些性质:
- 缩放:若 X 是均值为 0 的随机变量,则
Var(cX)=c2Var(X)
Var(X+Y)=Var(X)+Var(Y)
将这两条性质结合起来,就得到:
Var(aiϵi−1)=ai2Var(ϵi−1),Var(i∑Xi)=i∑Var(Xi)(当 Xi 相互独立)
而 Var(ϵi−1)=1,所以:
Var=i=1∑t(βij=i+1∏tαj)2=i=1∑t(βij=i+1∏tαj)
即要证明,对于所有正整数 t 有:
i=1∑t(βij=i+1∏tαj)=1−αˉt
其中
αˉt=s=1∏tαs,βi=1−αi
基础情况:t=1
当 t=1 时,左边的求和只有一项:
i=1∑1(βij=i+1∏1αj)=β1⋅1=β1
右边为:
1−αˉ1=1−α1
因为 β1=1−α1,所以等式成立
归纳假设:假设对于 t=k 成立
i=1∑k(βij=i+1∏kαj)=1−αˉk
归纳步骤:证明 t=k+1 时也成立
我们需要证明:
i=1∑k+1(βij=i+1∏k+1αj)=1−αˉk+1
其中 αˉk+1=αˉk⋅αk+1
将求和拆分为前 k 项和最后一项:
i=1∑k+1(βij=i+1∏k+1αj)=i=1∑k(βij=i+1∏k+1αj)+βk+1
注意到对于 1≤i≤k,有:
j=i+1∏k+1αj=(j=i+1∏kαj)⋅αk+1
因此,
i=1∑k(βij=i+1∏k+1αj)=αk+1i=1∑k(βij=i+1∏kαj)
根据归纳假设,
i=1∑k(βij=i+1∏kαj)=1−αˉk
所以上式变为:
αk+1(1−αˉk)
再加上最后一项 βk+1=1−αk+1:
αk+1(1−αˉk)+(1−αk+1)=1−αk+1αˉk
而
αˉk+1=αˉk⋅αk+1
所以我们得到:
i=1∑k+1(βij=i+1∏k+1αj)=1−αˉk+1
证毕
至此,对损失函数 L 的随机项进行随机梯度下降来实现高效训练。进一步地,通过将 L 重写为以下形式以减小方差:
L=Eq[−logp(xT)−t≥1∑logq(xt∣xt−1)pθ(xt−1∣xt)]⇒Eq[LTDKL(q(xT∣x0)∥p(xT))+t=2∑TLt−1DKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))−L0logpθ(x0∣x1)](5)
推导过程
⭐推导:
L⇒Eq[LTDKL(q(xT∣x0)∥p(xT))+t=2∑TLt−1DKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))−L0logpθ(x0∣x1)]
L=Eq[−logp(xT)−t=1∑Tlogq(xt∣xt−1)pθ(xt−1∣xt)]⇒t=TEq[−logp(xT)+logq(xT∣x0) ]+Eq[−t=1∑Tlogq(xt∣xt−1)pθ(xt−1∣xt)−logq(xT∣x0) ]=LTDKL(q(xT∣x0)∥p(xT))+Eq[−t=1∑Tlogpθ(xt−1∣xt)+t=1∑T−1logq(xt∣xt−1,x0)]⇒1<t≤TLT+t=2∑TDKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))=Lt−1Eq[−logpθ(xt−1∣xt)+logq(xt−1∣xt,x0)]−L0Eq[logpθ(x0∣x1)]
Eq.(5) 使用 KL 散度直接比较 pθ(xt−1∣xt) 与正向过程的后验分布,当以x0 为条件时,该后验分布具有解析解:
q(xt−1∣xt,x0)=N(xt−1;μ~t(xt,x0),β~tI)(6)
其中
μ~t(xt,x0):=1−αˉtαˉt−1βtx0+1−αˉtαt(1−αˉt−1)xtandβ~t:=1−αˉt1−αˉt−1βt(7)
因此,Eq.(5) 中的所有 KL 散度项均为高斯分布间的比较,可通过 Rao-Blackwell 化方法直接计算其闭式解,从而避免高方差的 Monte Carlo 估计
推导过程
⭐推导:
q(xt−1∣xt,x0)=N(xt−1;μ~t(xt,x0),β~tI)
其中
μt(xt,x0):=1−αˉtαˉt−1βtx0+1−αˉtαt(1−αˉt−1)xtandβt:=1−αˉt1−αˉt−1βt
正向过程
q(xt∣xt−1)=N(xt;αtxt−1,βtI),αt=1−βt
累积保留率
αˉt=s=1∏tαs,则有q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)
联合高斯分布(二元变量)
(xt−1xt)x0∼N(μ(αˉt−1x0αˉtx0),Σ((1−αˉt−1)Iαt(1−αˉt−1)Iαt(1−αˉt−1)I(1−αˉt)I))
条件高斯公式
对于
(uv)∼N((μu,μv),(Σuu,Σuv;Σvu,Σvv))
有
p(u∣v)=N(u;μu+ΣuvΣvv−1(v−μv),Σuu−ΣuvΣvv−1Σvu)
计算后验均值
- 令 u=xt−1,v=xt。
- Σuv=αt(1−αˉt−1)I,Σvv=(1−αˉt)I。
μt(xt,x0)=μu+ΣuvΣvv−1(xt−μv)=αˉt−1x0+1−αˉtαt(1−αˉt−1)(xt−αˉtx0)=1−αˉtαˉt−1(1−αt)x0+1−αˉtαt(1−αˉt−1)xt=1−αˉtαˉt−1βtx0+1−αˉtαt(1−αˉt−1)xt
计算后验方差
βtI=Σuu−ΣuvΣvv−1Σvu=(1−αˉt−1)I−1−αˉt(αt(1−αˉt−1))2I=1−αˉt(1−αˉt−1)βtI
最终后验分布(Eq.(6) & Eq.(7))
q(xt−1∣xt,x0)=N(xt−1;μ~t(xt,x0),β~tI) ,
μt(xt,x0)=1−αˉtαˉt−1βtx0+1−αˉtαt(1−αˉt−1)xt,βt=1−αˉt1−αˉt−1βt
我们暂不考虑通过重参数化学习 βt 的可能性,而是简单地将其设定为常数。在论文的实现中,后验分布 q 并不含可学习参数,因此 LT 在训练过程中为常数项,可在损失函数中忽略不计
我们接下来分析反向过程中的分布 p(xt−1∣xt),该分布被建模为高斯形式:
p(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))
对任意 1≤t≤T 均成立
首先,对于协方差 Σθ(xt,t),我们设置为时间相关的固定常数,即 Σθ(xt,t)=σt2I,且不参与训练。在实验中,σt2=βt 与 σt2=1−αˉt1−αˉt−1βt 均取得了相似的效果。前者适用于 x0∼N(0,I) 的情况,后者适用于将 x0 映射为固定值的情形。这两个选择在反向过程的熵约束中,分别对应于单位方差数据的上下界
接下来,我们引入对均值项 μθ(xt,t) 的一种特殊参数化形式,该形式的灵感来自对损失项 Lt 的分析
由 Eq.(4) 可知:
p(xt−1∣xt)=N(xt−1;μθ(xt,t),σt2I)
其对应的损失函数为:
Lt−1=Eq[2σt21∥μ^t(xt,x0)−μθ(xt,t)∥2]+C(8)
其中 C 为与 x0 无关的常数。因此,最直接的方式是令模型直接拟合 μ^t,即正向过程后验分布的均值
我们可以进一步重参数化该表达式,设 xt=αˉtx0+1−αˉtϵ,其中 ϵ∼N(0,I),代入 Eq.(7) 得:
Lt−1−C=Ex0,ϵ[2σt21μ^t(xt(x0,ϵ),αˉt1(xt(x0,ϵ)−1−αˉtϵ))−μθ(xt(x0,ϵ),t)2](9)
最终可化简为:
=Ex0,ϵ[2σt21αˉt1(xt(x0,ϵ)−1−αˉtβtϵ)−μθ(xt(x0,ϵ),t)2](10)
算法流程如下:
Eq.(10) 表明,在给定 xt 的条件下,μθ 能够重现表达式 αt1(xt−1−αˉtβtϵ)。既然 xt 是模型输入,我们采用以下参数化方式:
μθ(xt,t)=μ^t(xt,αt1(xt−1−αˉtϵθ(xt)))=αt1(xt−1−αˉtβtϵθ(xt,t))(11)
其中,ϵθ 是一个函数近似器,用于从输入 xt 中预测噪声项 ϵ。为了从 xt 得到 xt−1,有:
xt−1=αt1(xt−1−αˉtβtϵθ(xt,t))+σtz,z∼N(0,I)
这一完整的采样过程(即 Algorithm 2),在形式上类似于基于得分函数学习的 Langevin 动力学。此外,采用参数化形式 Eq.(11) 时,Eq.(10) 可进一步简化为:
Ex0,ϵ[2σt2αt(1−αˉt)βt2ϵ−ϵθ(αˉtx0+1−αˉtϵ,t)2](12)
这一无偏的多尺度噪声匹配损失正如文献 [55] 所述,可在不同噪声水平下联合训练。根据 Eq.(12),该目标等价于对 Langevin 型反向过程 Eq.(11) 所构造的变分下界进行优化
综上所述,我们通过将反向过程的均值函数 μθ 重新参数化为 μ^t,建立了一个能够预测噪声项 ϵ 的模型框架
假设图像数据由整数(取值范围为 {0,1,…,255})组成,并且这些整数被线性缩放到 [−1,1]。这确保了神经网络的反向过程始终在一致缩放的输入上运行,起始于标准正态先验 p(xT)
为了获得离散数据的对数似然,我们将反向过程的最后一项设置为一个独立的离散解码器,其从高斯分布 N(x0;μ0(x1,1),σ02I) 中生成:
p0(x0∣x1)=i=1∏D∫δ−(xi)δ+(xi)N(xi;μ0,i(x1,1),σ02)dx(13)
其中:
- D 表示数据的维度,i 上标表示提取特定坐标
- δ+(x) 和 δ−(x) 定义如下:
δ+(x)={∞x+2551x=255x<255,δ−(x)={−∞x−2551x=0x>0
在 VAE 解码器和自回归模型中,离散分布通常通过离散化连续分布来实现。我们的方法确保变分下界是离散数据的无损编码(lossless coding),无需在数据中添加噪声或在对数似然中引入缩放操作的雅可比行列式(Jacobian)。在采样结束时,在无噪声下展示 μθ(x1,1)
在上面定义的反向过程和解码器的基础上,变分下界(由 Eq.(12)和 Eq.(13) 推导而来)显然可以微分并用于训练
然而,我们发现使用以下变种形式的变分下界在采样质量和实现上均表现地更好:
Lsimple(θ)=Et,x0,ϵ[ϵ−ϵθ(αˉtx0+1−αˉtϵ,t)2](14)
其中,t 在 1 和 T 之间均匀分布。t=1 的情况对应于 L0,此时在离散解码器定义 Eq.(13) 中的积分被高斯概率密度函数乘以区间宽度来近似,忽略了 σ12 和边缘效应。对于 t>1 的情况,它们对应于 Eq.(12) 的一个 无权重版本,类似于 NCSN 去噪分数匹配模型 [55] 使用的损失加权方式(LT 没有出现,因为正向过程的方差 βt 是固定的)。Algorithm1 展示了使用该简化目标的完整训练过程。