| 🚀 问题类别 | ❌ 传统深层网络的局限性 | ✅ ResNet 的解决方案 |
|---|
| 深度退化问题 | 🚨 网络越深,训练误差反而上升,性能下降(如 56层 PlainNet > 20层) | ✨ 引入残差学习框架,通过学习残差函数 F(x),避免性能退化 |
| 梯度消失/爆炸 | 🚨 反向传播中梯度在深层中可能指数衰减/增长,导致难以训练 | ✨ 跳跃连接提供“梯度高速通道”,保持梯度稳定,提升训练可行性 |
| 表达能力受限 | 🚨 深层网络难以优化,陷入局部极值,特征学习不充分 | ✨ ResNet 允许直接传递输入特征,使网络更易学习有效映射 |
| 准确率饱和 | 🚨 增加网络深度后,准确率不再提升,甚至下降 | ✨ ResNet 提高了可训练深度(上千层),保持模型表现提升趋势 |
| 特征信息退化 | 🚨 层层堆叠会逐步损失原始特征,信息难以穿透深层 | ✨ Shortcut Connection 直接传递输入,保留原始特征,增强表示能力 |
| 结构扩展困难 | 🚨 传统网络越深越难设计,参数量大,计算代价高 | ✨ 采用模块化设计(基本残差块+瓶颈块),高效扩展至 ResNet-152+ |
ResNet 的模型结构如下:
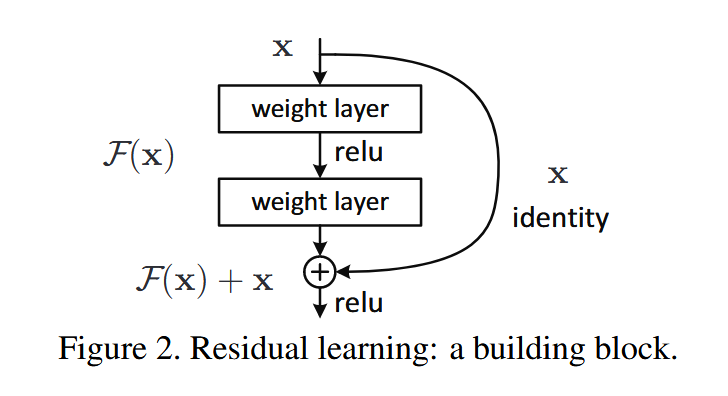
ResNet 将传统网络层的目标从学习完整映射改为残差函数
关注一个网络的局部,x 作为当前部分的输入,其已经涵盖了之前训练过的信息
Plain Network 通过 x 得到期望的 H(x),直接学习 H(x)(H(x) 是未知的,我们需要通过训练来找到,学习就是通过数据去拟合目标映射 H(x))
ResNet 则是学习 F(x)=H(x)−x ,原始期望学习到的映射改写为 H(x)=F(x)+x
通过 残差连接(Shortcut/Residual Connections) 实现输入与输出的逐元素相加,并将残差块定义为:
y=F(x,Wi)+x
当 恒等映射(Identity Mapping) 为最优解时(即 H(x)=x),残差项 F(x)→0
由于使用残差连接后只是单纯与 x 进行了连接,没有引入额外的参数或是增大计算复杂度,能够有效节省开销
残差连接在结构图中表示为通过恒等映射的箭头,将输入 x 跳过一层或多层,直接加到后面某层的输出上
残差连接的优点如下:
- 梯度稳定化: 跳跃连接为反向传播提供“高速公路”,保持梯度范数稳定,缓解梯度消失/爆炸
- 信息无损传递: 输入特征直接传递到后续层,避免特征退化
- 动态深度调节: 冗余层可通过学习 F(x) 自动失效,网络实际深度自适应
奇异值
对一个任意实矩阵 A∈Rm×n,我们可以对它进行奇异值分解(SVD):
A=UΣVT
其中:
U∈Rm×m:正交矩阵(列向量正交且单位)
V∈Rn×n:正交矩阵
Σ∈Rm×n:对角矩阵,对角线上是非负实数:
σ1≥σ2≥⋯≥σr>0
它们就叫做奇异值(singular values)
奇异值的数学计算 —— 奇异值等价于:
ATA 的 特征值的平方根
即:
If λi is an eigenvalue of ATA, then σi=λi
谱范数
谱范数(Spectral Norm) 是一个矩阵的重要“大小度量”,定义如下:
对于一个矩阵 A∈Rm×n,其谱范数是:
∥A∥2=∥x∥2=1sup∥Ax∥2
也就是说: 谱范数是这个矩阵对任意单位向量能“放大”的最大程度。
它等于 A 的最大奇异值(Singular Value)
在神经网络中,每一层本质上就是一个矩阵 Wl,对输入进行线性变换。反向传播时,梯度会不断乘以各层的导数矩阵:
- 如果某层的导数矩阵的 谱范数大于 1,它就会“放大梯度”
- 如果 谱范数小于 1 ,就会“压缩梯度”
关于梯度消失/爆炸
⭐一般深层网络(plain deep netwok)的 梯度消失:
对于一层简单的前向映射:
h=σ(Wx)
其中 σ 是激活函数(如 ReLU、sigmoid、tanh 等)
若堆叠 L 层,第 L 层输出为
h(L)=fL(fL−1(⋯f1(x)⋯))
反向传播时,损失 L 关于第一层权重 W1 的梯度为:
∂W1∂L=∂h(L)∂L⋅k=2∏L∂h(k−1)∂h(k)⋅∂W1∂h(1)链式法则
当许多 ∂h(k−1)∂h(k) 的谱范数小于 1 时,整个乘积趋于 0,即梯度消失,这会导致:
- 权重不更新: 经由反向传播导致最外层(前面的层)的梯度很小,致前几层的权重“学不到东西”,无法更新
- 收敛缓慢: 前几层训练非常慢甚至停滞,整个模型训练周期加长
- 无法学习长期依赖: 尤其在 RNN/LSTM 中,梯度消失意味着无法捕捉长时间跨度的信息,无法学习长期依赖
⭐一般深层网络(plain deep netwok)的 梯度爆炸:
同理,如果某些 ∥∂h(k)/∂h(k−1)∥≫1,整个乘积呈指数级增长,最终变得极大,即梯度爆照,这会导致:
- 权重发散: 权重更新太大,损失变为 NaN
- 训练不稳定: Loss 波动剧烈甚至震荡,模型完全无法收敛
- 数值精度溢出: 某些数值操作可能超过计算机表示范围,报错或 NaN
残差连接的设计巧妙地解决了梯度消失/爆炸问题,使得训练深层网络成为了可能。下面从数学角度简单分析 ResNet 是如何解决梯度问题的:
ResNet 如何解决梯度消失?
考虑一个仅含一个残差块的简化反向流:
y=F(x)+x,L=ℓ(y)
对输入 x 求梯度:
∂x∂L=∂y∂L⋅∂x∂y=∂y∂L(可能小∂x∂F(x)+恒等映射I)
- 关键:哪怕 ∂x∂F 很小,由于加上了恒等映射 I,整体雅可比矩阵的谱范数下界至少是 1
换言之,梯度借由恒等映射将之前学到的内容 x 从后层直接传到前层,不会在每个块中再被小于 1 的因子衰减
在多个残差块级联时,链式相乘变为:
∂x∂L=∂yL∂Lk=1∏L(∂yk−1∂Fk+I),
由于每项都包含 I,即使残差分支衰减,恒等通路始终保留了完整的梯度流
对于梯度爆炸,在现代的神经网络中,通过 BatchNorm、合理初始化、合理的 F 架构(如小卷积核、激活后加 BN 等)控制每一层的雅可比矩阵的谱范数 ∥JF∥2<1(梯度爆炸已经不是主要问题),从而主要关注防止梯度消失
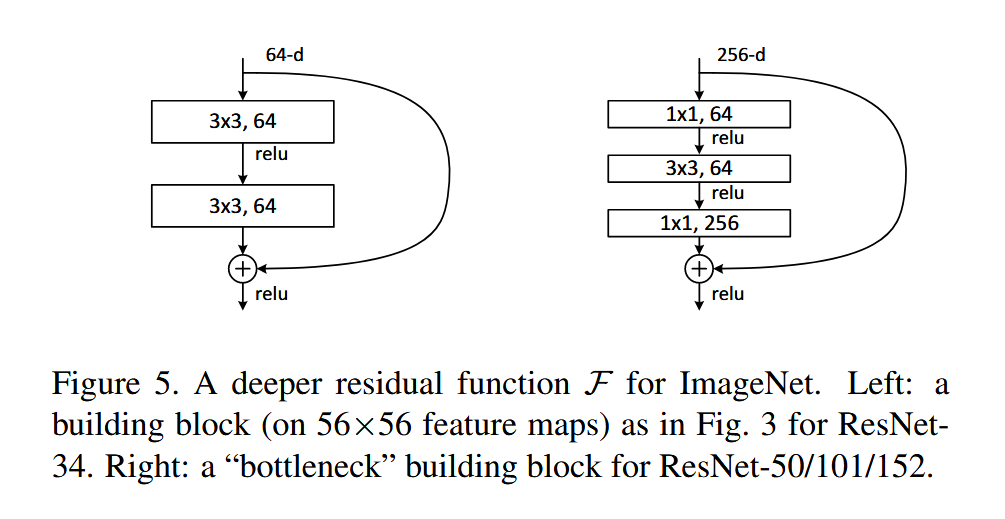
Bottleneck 核心在于先压缩后扩张,类似于一个“瓶颈”的形状,能够减少参数量。下面是对 ResNet 中的设计进行简单分析:
第一层 1×1 卷积:
- 通道数从 C → C/4,压缩特征维度
- 作用:减少后续 3×3 卷积的计算量和参数
第二层 3×3 卷积:
- 在低维空间(通道数只有 C/4)进行空间特征提取
- 作用:完成核心的感受野扩张和非线性表示
第三层 1×1 卷积:
- 通道数从 C/4 → C,恢复原始维度
- 作用:将低维特征映射回高维空间,以便与主分支相加
计算和参数效率
只用了原本 C2(单层 3×3)的 87.5% 参数,还能获得更深的网络